技术分享

首先向一个 Url 地址发送请求,随后远端服务器将会返回整个网页。
常规情况下,当我们使用浏览器访问网站也是这么一个流程:用户在浏览器输入一个地址,浏览器将会发送一个服务器请求,服务器返回请求的内容,随后浏览器解析内容。其次,发送请求后,将会得到整个网页的内容。最后,通过我们的需求去解析整个网页,通过正则或其它方式获取需要的数据。
requests.get() ----get请求方法
1.requests.get(
url=请求url,
headers=请求头字典,
params=请求参数子弹,
timeout=超时时长,
)----- 返回一个response对象
2.response对象的属性
服务器响应包含:状态行(协议,状态码)、响应头、空行、响应正文。
(1)响应正文:
字符串格式:response.text
bytes类型:response.content
(2)状态码:response.status_code
(3)响应头:response.headers(字典)
response.headers('cookie')
(4)响应正文的编码:response.encoding
respons.text获取到的字符串类型的响应正文,其实是通过下面的步骤获取的:
response.text=response.content.decode(response.encoding)
(5)乱码问题的解决办法:
产生的原因:编码和解码的编码格式不一致造成的
str.encode('编码')---将字符串按指定编码解码成bytes类型
bytes.decode('编码')---将bytes类型按指定编码编码成字符串
解决方法:
解决一:response.content.decode('页面正确的编码格式')
解决二:找到正确的编码,设置到response.encoding中
response.encoding=正确的编码
response.text--->正确的页面内容
3.get请求小结:
(1)没有请求参数的情况下,只需要确定url和headers字典
(2)get请求是有请求参数
在chrome浏览器中,下面找query_string_params,将里面的参数封装到params字典中。
(3)分页主要是查看每页中,请求参数页码字段的变化,找到变化规律,用for循环就可以做到分页。post请求方法
requests.post( url=请求url, headers=请求头字典, data=请求数据字典, timeout=超时时长, )-----返回response对象 post请求一般返回数据都是json数据 *解析json数据的方法: 1.response.json() ---- json字符串所对应的python的list或者dict 2.用json模块: json.loads(json_str) --->json_data(python的list或者dict) json.dumps(json_data)--->json_str post请求能否成功,关键看请求参数。 如何查找是哪个请求参数在影响数据获取?---通过对比,找到变化的参数。 变化参数如何找到参数的生成方式,就是解决这个ajax请求数据获取的途径。 寻找的办法有以下几种: (1)写死在页面 (2)写在js中 (3)请求参数是在之前的一条ajax请求的数据里面提前获取好的。
最简单的一个爬虫示例:获取百度页面
import requests
url="https://www.baidu.com/"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/64.0.3282.119 Safari/537.36'}
html=requests.get(url,headers=headers)
print(html.text)import requests:引入 requests 模块
url="https://www.baidu.com/":设置要请求的url值,这里为百度。
headers:为了更好的伪造自己是浏览器访问的,需要加一个头,让自己看起来是通过浏览器访问。
html=requests.get(url,headers=headers):requests使用get方法,请求网站为url设置的值,头部为headers。
print(html.text):显示返回的值html中的text文本,text文本则为网页的源代码。
接下来使用BeautifulSoup库解析,使用bs4可以快速的让我们获取网页中的一般信息,例如我们需要获取刚刚得到网页源码中的title标题,首先引入 bs库。
随后使用 beautifulsoup 进行解析,html.parser 代表html的解析器,可以解析html代码;其中 html.text 为网页源码为html。
完整代码示例
import requests
from bs4 import BeautifulSoup
url="https://www.baidu.com/"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/64.0.3282.119 Safari/537.36'}
html=requests.get(url,headers=headers)
val = BeautifulSoup(html.text, 'html.parser')
print(val.title)
f = open(r'D:html.html',mode='w')
f.write(html.text)
f.close()以上代码可能会出现编码不一致,出现“乱码”的情况,可以通过以下方式解决:
f = open(r'D:html.html',mode='w',encoding="utf-8")
最终打开保存的文件如下:
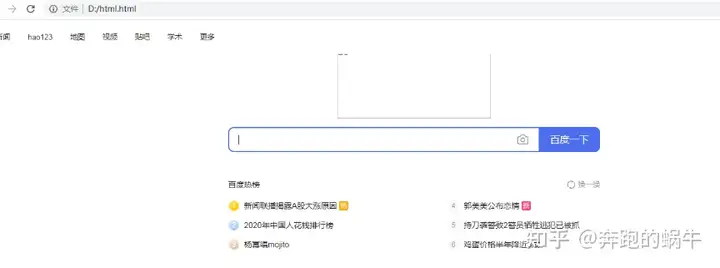
由于有些资源是动态加载,获取的链接有时效性,所以并没有显示。